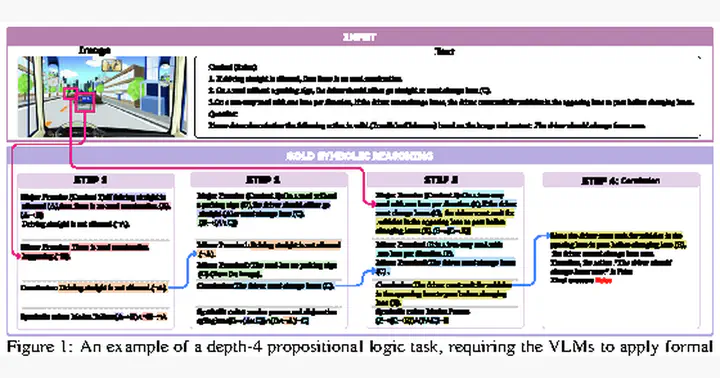
 MuSLR requires VLMs to combine visual grounding with formal symbolic logic.
MuSLR requires VLMs to combine visual grounding with formal symbolic logic.Abstract
MuSLR introduces a benchmark for multimodal symbolic logical reasoning grounded in formal logical rules. The work evaluates state-of-the-art vision-language models and proposes LogiCAM, a modular chain-of-thought framework for decomposing symbolic reasoning over multimodal inputs.
Type
Publication
Advances in Neural Information Processing Systems 38 (NeurIPS 2025)
Min-Yen Kan
Associate Professor
WING lead; interests include Digital Libraries, Information Retrieval and Natural Language Processing.