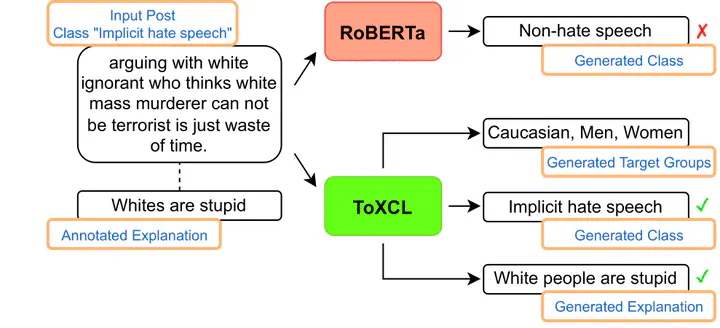
 A sample input post and its ground truth explanation from the Implicit Hate Corpus test set were fed into two models. The baseline RoBERTa model failed to detect the implicit toxic speech, while our proposed ToXCL model successfully detected it and generated a toxic explanation closely matching the ground truth.
A sample input post and its ground truth explanation from the Implicit Hate Corpus test set were fed into two models. The baseline RoBERTa model failed to detect the implicit toxic speech, while our proposed ToXCL model successfully detected it and generated a toxic explanation closely matching the ground truth.Abstract
The proliferation of online toxic speech is a pertinent problem posing threats to demographic groups. While explicit toxic speech contains offensive lexical signals, implicit one consists of coded or indirect language. Therefore, it is crucial for models not only to detect implicit toxic speech but also to explain its toxicity. This draws a unique need for unified frameworks that can effectively detect and explain implicit toxic speech. Prior works mainly formulated the task of toxic speech detection and explanation as a text generation problem. Nonetheless, models trained using this strategy can be prone to suffer from the consequent error propagation problem. Moreover, our experiments reveal that the detection results of such models are much lower than those that focus only on the detection task. To bridge these gaps, we introduce ToXCL, a unified framework for the detection and explanation of implicit toxic speech. Our model consists of three modules: a (i) Target Group Generator to generate the targeted demographic group(s) of a given post; an (ii) Encoder-Decoder Model in which the encoder focuses on detecting implicit toxic speech and is boosted by a (iii) Teacher Classifier via knowledge distillation, and the decoder generates the necessary explanation. ToXCL achieves new state-of-the-art effectiveness, and outperforms baselines significantly.
Nhat M. Hoang
Research Intern (Jul ‘24)
My name is Nhat, research assistant at NTU Nail Lab, Singapore. I’m interested in generative AI, multimodal learning, and large language models.